

2·
1 day agoWhat other wearable is more efficient?

What other wearable is more efficient?

If you do named parameters in rust, you would need to set every parameter.
If that’s the condition, yeah, it’s bad. The good thing about how Python handles it is that they can still be mandatory or optional. And that makes it a more flexible option than the builder pattern because it applies to any function or method.
you can have a better data structure in any language, but rarely someone will bother doing that for booleans
yeah, the widest adopted solutions are truly the shittiest.
My university spent a few years trying out different options, only to land on Canvas about 3 years ago. They must have good sales people.
This! There’s also a longstanding open issue on rust to allow a similar way to pass keyword/named arguments. IMO every modern language should have something like this. Makes all the difference when reading code.
Inlay hints from your editor are a good help, but this should be built into the language.
I feel you. I don’t particularly like any frontend work, but desktop frameworks can go to hell. No wonder why electron apps took off in the last decade, despite all its problems.
yeah, subagents is what I use all the time to tame context size in opencode

right, but remote code execution comes in many different ways. Having a machine vulnerable to this kind of privilege escalation is a really bad thing.
We know your full name, blood type, and that your left elbow is itching a bit right now. Your browser told us. But we’re choosing to not show you. We also know what you did on July 14, 2018.
This is evil. Fuck it. I want nothing to do with these cunts anymore. I’m degoogling this year.
how do you do, fellow human
I too, enjoy the company of blackjack and to play hookers

I’ve always enjoyed just using a hyphen surrounded by spaces for readability - but even I am hesitant to do that lately
I was wondering the other day if there is a list of LLM-isms somewhere, like “It’s not X, but Y”, em-dashes, overly confident statements, etc
edit: https://github.com/NousResearch/autonovel/blob/master/ANTI-SLOP.md
wdym by duplicating?
not bad, I’ll keep myself a fake stache around just in case
good, I’ll add vetted models to my blocklist

micro for sensible defaults out of the box, and because I don’t like modal editors.
Bitwarden’s npm distribution pipeline stayed compromised for approximately 19 hours and 334 developers had enough time to pull the malicious package before it was caught.
It was actually about 90 minutes
Everyone running bw in a CI pipeline just handed the attackers whatever else happened to live on that machine.
only if they installed bw in that time window
Otherwise yes, I agree it’d be better if the CLI was written in a non-JS/TS ecosystem. Perhaps Rust or Go. And the criticisms to list including secrets are super valid.
ah right, and my eyes need to be recreated because they can’t see ultraviolet
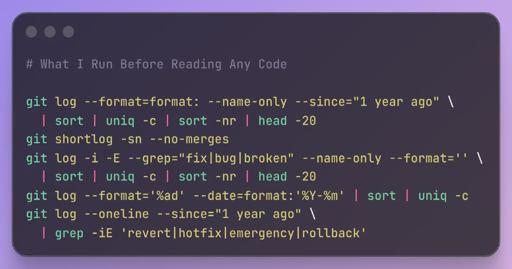





that’s what happens when the western alternatives are 10x more expensive